Testando múltiplos modelos supervisionados & tunados!
By [map[name:Lucas Moraes.] map[url:https://lucasmoraes.org]] in machine learning tidymodels
March 11, 2022
Neste post, vou usar novamente o {tidymodels}, mas com a intenção de explorar algumas funcionalidades ao invés de implementar e interpretar os modelos em si.
Vou montar um fluxo de trabalho, onde comparo a performance de três modelos supervisionados de classificação (regressão logística, random forest e XGBoost), tunando diferentes hiperparâmetros em cada usando uma busca em grid. Além disso, também vou comparar como diferentes combinações de preditores e etapas de pré-processamento podem influenciar na performance dos mesmos.
Meu objetivo aqui não é realizar um projeto de modelagem do início ao fim. Não irei realizar uma análise exploratória dos dados, nem interpretar os resultados dos modelos. Quero apenas mostrar como a performance de diferentes modelos pode ser analisada usando o framework do {tidymodels}, aumentando a escala de projetos e análises em potencial.
Para esta análise irei usar dados referentes aos atributos de Pokemons. Não se deixe enganar, este dataset é uma ótima ferramenta de testes, pois possui variáveis de todos os tipos, categorias e distribuições.
Existe um tipo especial e raro de pokemon, chamado lendário. Esta será minha variável de resposta, sendo ela binária.
Meus dados crus consistem no dataset pokemon.csv. Este possui uma quantidade enorme de informações, mas vou selecionar apenas algumas, para simplificar o processo.
Novamente, minha intenção aqui é mostrar como este tipo de pipeline pode auxiliar no processo de escolha do modelo a utilizar para um problema. O {tidymodels} tem se mostrado uma ferramenta muito poderosa nesse sentido, permitindo executar essas análises de maneira intuitiva e com sintaxe simples.
Lendo os dados
Primeiramente vou ler a tabela que encontra-se nesta pasta do dropbox e registrar os processadores para agilizar a velocidade das análises:
# chamando pacotes
library(tidyverse)
library(janitor)
library(tidymodels)
library(xgboost)
# puxando tabela
df_pokemon <-
read_csv("https://www.dropbox.com/s/loim4redam6feoy/pokemon.csv?dl=1") %>%
clean_names()
# registrando cpu's para o processamento paralelo
library(doParallel)
all_cores <- parallel::detectCores(logical = FALSE)
registerDoParallel(cores = all_cores)
Em seguida vou extrair apenas os dados que preciso e formatá-los:
df_model <-
df_pokemon %>%
select(is_legendary,sp_attack,sp_defense, # extraindo apenas essas 5 variáveis
speed,attack,defense,type1) %>%
mutate_if(is.character,as.factor) %>% # convertendo strings para fatores
mutate(is_legendary=as.factor(is_legendary)) %>% # convertendo y para fator
relocate(is_legendary) %>% # perfumaria - trazendo var pra frente
na.omit() # Omitindo os NA (não recomendado!)
Desse modo tenho minha variável de resposta is_legendary e algumas outras variáveis (ataque e ataque especial, defesa e defesa especial, velocidade e tipo primário) que escolhi como explicativas. Todas variáveis explicativas são numéricas com a exceção do tipo primário, que assume categorias distintas (e.g.: fogo, água, etc…).
Abaixo, uma visão geral da tabela:
df_model %>% glimpse()
## Rows: 801
## Columns: 7
## $ is_legendary <fct> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
## $ sp_attack <dbl> 65, 80, 122, 60, 80, 159, 50, 65, 135, 20, 25, 90, 20, 25…
## $ sp_defense <dbl> 65, 80, 120, 50, 65, 115, 64, 80, 115, 20, 25, 80, 20, 25…
## $ speed <dbl> 45, 60, 80, 65, 80, 100, 43, 58, 78, 45, 30, 70, 50, 35, …
## $ attack <dbl> 49, 62, 100, 52, 64, 104, 48, 63, 103, 30, 20, 45, 35, 25…
## $ defense <dbl> 49, 63, 123, 43, 58, 78, 65, 80, 120, 35, 55, 50, 30, 50,…
## $ type1 <fct> grass, grass, grass, fire, fire, fire, water, water, wate…
Particionando a amostra e criando receitas
Em seguida vou dividir minha amostra em partições de treino, teste e replicatas de validação cruzada:
set.seed(123)
df_split <-
initial_split(df_model,strata=is_legendary) # dividindo as partições
df_train <- training(df_split) # Extraindo df de treino
df_test <- testing(df_split) # Extraindo df de teste
df_folds <- vfold_cv(df_train) # Criando replicatas por cv
Agora posso criar diferentes “receitas” que serão testadas. Estas consistem nas fórmulas que quero testar (quais variáveis incluir, no caso) e algumas transformações que podem ser feitas nos dados (normalização de variáveis contínuas, por exemplo).
Abaixo um exemplo. Nesta receita, estou usando apenas o ataque e a defesa como variáveis explicativas. Além disso, estou normalizando ambas variáveis, que são numéricas. Também estou corrigindo o desbalanço de classes por downsampling.
receita1 <-
recipe(is_legendary ~ attack + defense,data=df_train) %>% # formula
themis::step_downsample(is_legendary) %>% # downsampling
step_normalize(all_numeric_predictors()) # normalização
Em seguida vou criar mais duas receitas, uma igual a acima, adicionando o ataque e defesa especiais dos pokemon. Na terceira, vou incluir todos dados:
receita2 <-
recipe(is_legendary ~ sp_attack + sp_defense,data=df_train) %>% # diferente aqui
themis::step_downsample(is_legendary) %>% # downsampling
step_normalize(all_numeric_predictors()) # normalização
receita3 <-
recipe(is_legendary ~ .,data=df_train) %>% # todos dados
themis::step_downsample(is_legendary) %>% # downsampling
step_normalize(all_numeric_predictors()) %>% # normalização
step_dummy(type1) # encoding da var categórica para o xgboost
Tunagem de hiperparâmetros
Como havia mencionado, quero testar como três modelos diferentes se ajustam aos meus dados: a regressão logística, o random forest e o XGBoost. Além disso, quero testar a performance dos modelos com diferentes valores para seus parâmetros, através da busca em grid.
Faço isso configurando cada modelo, deixando como tune() os argumentos que correspondem aos parâmetros que quero incluir no grid:
log_reg <- # Regressão logística
logistic_reg(penalty = tune()) %>% # Tunar penalidade
set_engine("glmnet")
rf_spec <- # Random Forest
rand_forest(mtry = tune(), # Tunar total de features em cada nó
min_n = tune(), # Tunar quantidade de dados para um split
trees = 1000) %>%
set_engine("ranger") %>%
set_mode("classification")
xgb_spec <- # XGBoost
xgboost_model <-
parsnip::boost_tree(
mode = "classification",
trees = 1000,
min_n = tune(),# Tunar quantidade de dados para um split
tree_depth = tune(), # Tunar complexidade da árvore
learn_rate = tune(), # Tunar taxa de aprendizado
loss_reduction = tune() # Tunar função de perda
) %>%
set_engine("xgboost")
Executando o grid
Tenho 3 receitas, 3 modelos e uma série de hiperparâmetros em cada modelo para testar. Com o {tidymodels}, posso juntar toda essa informação em uma única variável, usando listas nomeadas e a função workflow_set, que aceita as receitas e as especificações dos modelos como input:
modelos_e_receitas <-
workflow_set(
preproc = list(receita1 = receita1, # Incluindo receitas
receita2 = receita2,
receita3 = receita3),
models = list(xgb_spec = xgb_spec, # Incluindo especificações dos modelos
rf_spec = rf_spec,
log_reg=log_reg))
A partir desse objeto, posso executar um map estilo purrr, usando a função workflow_map que vai combinar todas possibilidades nas amostras da validação cruzada. Isso significa que cada combinação (de receita, modelo e hiperparâmetros) será testada em 10 replicatas dos dados de treino e a média das métricas de performance resultantes será extraída. Propositadamente, defini o parâmetro verbose = TRUE para que conforme os ajustes andam, eu saiba o que está acontecendo:
controle <-
control_grid(
save_pred = FALSE,
parallel_over = "everything",
save_workflow = TRUE,
extract = extract_model
)
grid_output <-
modelos_e_receitas %>%
workflow_map(
seed = 1503, # Deixando reprodutível
resamples = df_folds, # usando replicatas
grid = 25, # Limitando tamanho do grid
verbose = TRUE, # Print do andamento
control = controle # Atributos de controle definidos acima
)
## i 1 of 9 tuning: receita1_xgb_spec
## ✔ 1 of 9 tuning: receita1_xgb_spec (1m 34.7s)
## i 2 of 9 tuning: receita1_rf_spec
## i Creating pre-processing data to finalize unknown parameter: mtry
## ✔ 2 of 9 tuning: receita1_rf_spec (28s)
## i 3 of 9 tuning: receita1_log_reg
## ✔ 3 of 9 tuning: receita1_log_reg (2.2s)
## i 4 of 9 tuning: receita2_xgb_spec
## ✔ 4 of 9 tuning: receita2_xgb_spec (1m 36.5s)
## i 5 of 9 tuning: receita2_rf_spec
## i Creating pre-processing data to finalize unknown parameter: mtry
## ✔ 5 of 9 tuning: receita2_rf_spec (27.6s)
## i 6 of 9 tuning: receita2_log_reg
## ✔ 6 of 9 tuning: receita2_log_reg (2.3s)
## i 7 of 9 tuning: receita3_xgb_spec
## Warning in mclapply(argsList, FUN, mc.preschedule = preschedule, mc.set.seed
## = set.seed, : scheduled core 2 did not deliver a result, all values of the job
## will be affected
## ✔ 7 of 9 tuning: receita3_xgb_spec (1m 39.7s)
## i 8 of 9 tuning: receita3_rf_spec
## i Creating pre-processing data to finalize unknown parameter: mtry
## Warning in mclapply(argsList, FUN, mc.preschedule = preschedule, mc.set.seed =
## set.seed, : scheduled cores 3, 6 did not deliver results, all values of the jobs
## will be affected
## ✔ 8 of 9 tuning: receita3_rf_spec (36.1s)
## i 9 of 9 tuning: receita3_log_reg
## ✔ 9 of 9 tuning: receita3_log_reg (2.6s)
Explorando os resultados
A primeira coisa que consideraria interessante, antes de selecionar os melhores resultados, seria comparar a performance dos modelos. Isso pode ser feito usando a função autoplot (que resulta em um objeto de classe ggplot), a partir dos resultados do grid:
autoplot(
grid_output,
rank_metric = "roc_auc",
metric = "roc_auc",
select_best = TRUE
) +
theme_bw() + # Perfumaria em cima do plot :)
theme(axis.title.x=element_blank(),
axis.text.x=element_blank(),
axis.ticks.x=element_blank())
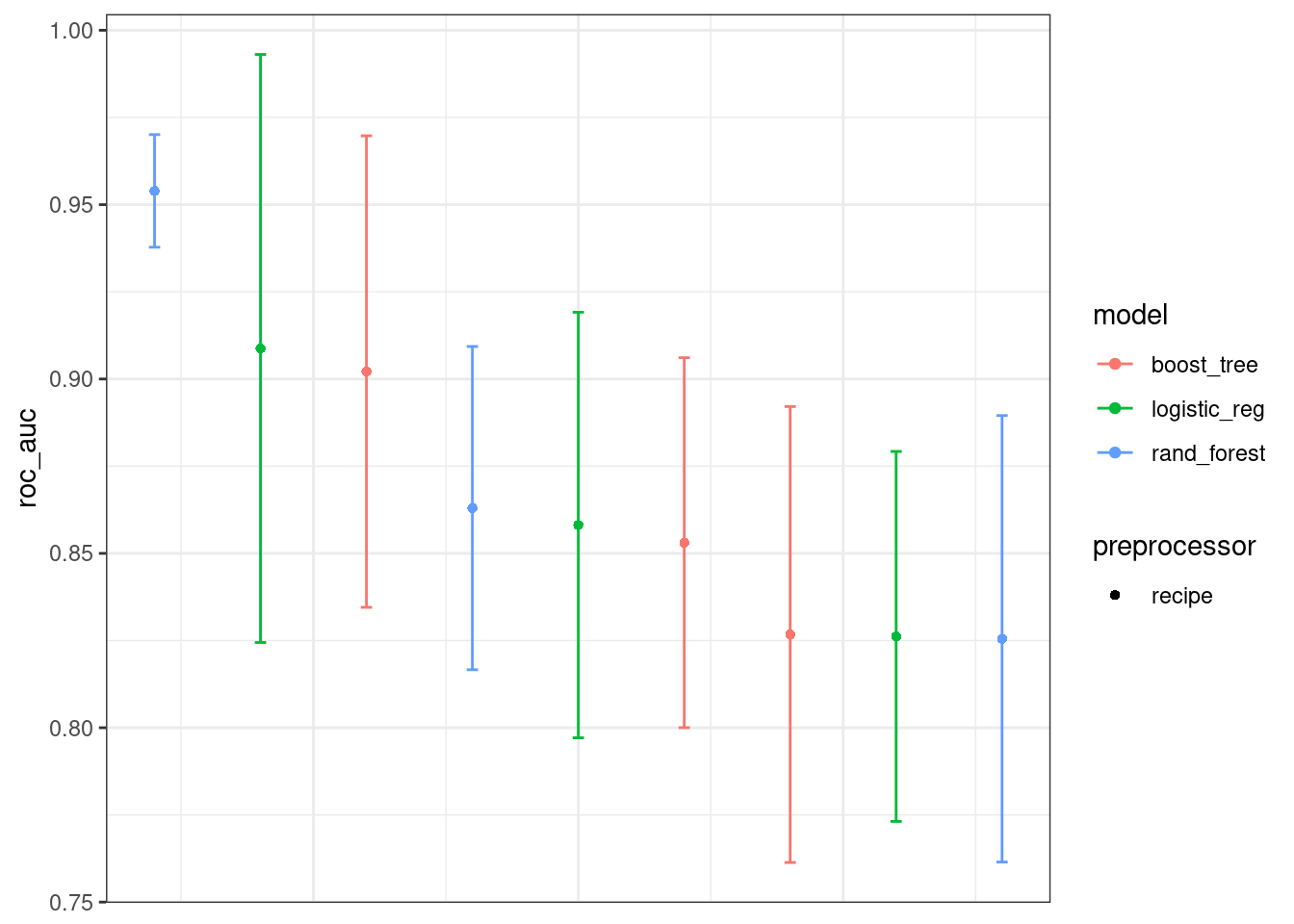
Cada ponto representa um modelo e uma receita, tendo seus intervalos de confiança medidos com base na tunagem dos hiperparâmetros.
Também é possível rankear os resultados da tabela. Abaixo estou selecionando os 10 melhores modelos em relação aos valores médios de AUC, encontrados nos testes de validação cruzada:
knitr::kable(
grid_output %>%
rank_results() %>%
filter(.metric == 'roc_auc') %>%
arrange(desc(mean)) %>%
select(wflow_id,.metric,mean,model) %>%
head()
)
| wflow_id | .metric | mean | model |
|---|---|---|---|
| receita3_rf_spec | roc_auc | 0.9539294 | rand_forest |
| receita3_rf_spec | roc_auc | 0.9515351 | rand_forest |
| receita3_rf_spec | roc_auc | 0.9486467 | rand_forest |
| receita3_rf_spec | roc_auc | 0.9458058 | rand_forest |
| receita3_rf_spec | roc_auc | 0.9414859 | rand_forest |
| receita3_rf_spec | roc_auc | 0.9368465 | rand_forest |
Nesse caso, o melhor modelo foi o receita3_rf_spec, que teve maior AUC média. Lembrando, este é um modelo do tipo random forest que leva em consideração todos os dados que selecionei da tabela, com normalização das variáveis contínuas e downsampling da variável de resposta.
Além disso diversos hiperparâmetros foram testados para todos modelos. Eu poderia inspecionar a variável grid_output de diversas formas, para entender os valores específicos de performance para cada combinação de hiperparâmetro em cada replicata da validação cruzada. Isso pode ser trabalhoso (embora as vezes necessário) e, ao invés de seguir por esse caminho, posso ranquear novamente cada caso, dentro da receita escolhida:
knitr::kable(
grid_output %>%
extract_workflow_set_result("receita3_rf_spec") %>%
collect_metrics() %>%
filter(.metric=="roc_auc") %>%
arrange(desc(mean))
)
| mtry | min_n | .metric | .estimator | mean | n | std_err | .config |
|---|---|---|---|---|---|---|---|
| 7 | 2 | roc_auc | binary | 0.9539294 | 7 | 0.0098178 | Preprocessor1_Model19 |
| 7 | 22 | roc_auc | binary | 0.9515351 | 8 | 0.0121038 | Preprocessor1_Model16 |
| 19 | 25 | roc_auc | binary | 0.9486467 | 8 | 0.0138041 | Preprocessor1_Model08 |
| 19 | 9 | roc_auc | binary | 0.9458058 | 7 | 0.0122021 | Preprocessor1_Model11 |
| 16 | 26 | roc_auc | binary | 0.9414859 | 7 | 0.0131308 | Preprocessor1_Model03 |
| 12 | 39 | roc_auc | binary | 0.9368465 | 8 | 0.0165164 | Preprocessor1_Model24 |
| 17 | 19 | roc_auc | binary | 0.9325774 | 8 | 0.0302957 | Preprocessor1_Model07 |
| 20 | 17 | roc_auc | binary | 0.9310903 | 8 | 0.0303220 | Preprocessor1_Model15 |
| 21 | 12 | roc_auc | binary | 0.9291851 | 8 | 0.0301762 | Preprocessor1_Model20 |
| 1 | 15 | roc_auc | binary | 0.9204132 | 8 | 0.0409642 | Preprocessor1_Model23 |
| 13 | 28 | roc_auc | binary | 0.9172246 | 8 | 0.0401992 | Preprocessor1_Model04 |
| 11 | 38 | roc_auc | binary | 0.9152635 | 8 | 0.0446689 | Preprocessor1_Model12 |
| 4 | 5 | roc_auc | binary | 0.9116951 | 7 | 0.0429818 | Preprocessor1_Model10 |
| 14 | 16 | roc_auc | binary | 0.9089189 | 7 | 0.0408479 | Preprocessor1_Model21 |
| 11 | 33 | roc_auc | binary | 0.9082606 | 8 | 0.0401483 | Preprocessor1_Model09 |
| 17 | 35 | roc_auc | binary | 0.9078784 | 8 | 0.0384864 | Preprocessor1_Model25 |
| 8 | 30 | roc_auc | binary | 0.9078225 | 8 | 0.0420805 | Preprocessor1_Model17 |
| 5 | 5 | roc_auc | binary | 0.9077732 | 7 | 0.0452007 | Preprocessor1_Model02 |
| 21 | 37 | roc_auc | binary | 0.9070498 | 8 | 0.0368612 | Preprocessor1_Model01 |
| 9 | 11 | roc_auc | binary | 0.9059694 | 7 | 0.0453481 | Preprocessor1_Model05 |
| 2 | 14 | roc_auc | binary | 0.9013566 | 7 | 0.0470592 | Preprocessor1_Model13 |
| 10 | 7 | roc_auc | binary | 0.9006260 | 7 | 0.0437577 | Preprocessor1_Model22 |
| 6 | 32 | roc_auc | binary | 0.9003536 | 7 | 0.0495620 | Preprocessor1_Model18 |
| 15 | 21 | roc_auc | binary | 0.9000487 | 7 | 0.0418261 | Preprocessor1_Model14 |
| 3 | 24 | roc_auc | binary | 0.8996576 | 7 | 0.0519144 | Preprocessor1_Model06 |
Alternativamente poderia simplesmente selecionar o melhor conjunto de hiperparâmetros usando a função select_best:
knitr::kable(
grid_output %>%
extract_workflow_set_result("receita3_rf_spec") %>%
select_best(metric = "roc_auc")
)
| mtry | min_n | .config |
|---|---|---|
| 7 | 2 | Preprocessor1_Model19 |
Mas nem sempre faz sentido usar a configuração mais performática no treino, pois ela pode estar performando bem por overfitting!
Implementando na partição de teste
Neste post estou ignorando coisas que não devem ser ignoradas, pois meu objetivo é mostrar o pipeline!
Sendo assim, vou então selecionar meu melhor modelo e os melhores hiperparâmetros, para fazer o ajuste final de meus dados.
Vou repetir o último passo, mas armazenando os resultados em uma variável:
best_results <-
grid_output %>%
extract_workflow_set_result("receita3_rf_spec") %>%
select_best(metric = "roc_auc")
Uso ela para fazer o ajuste na partição de treino inteira (lembrando que até agora ajustei os dados nas replicatas). A função last_fit além de fazer isso, já aplica o modelo na partição de teste:
boosting_test_results <-
grid_output %>%
extract_workflow("receita3_rf_spec") %>%
finalize_workflow(best_results) %>%
last_fit(split = df_split)
Com isso, posso ver como o modelo final performa na partição de teste:
collect_metrics(boosting_test_results)
## # A tibble: 2 × 4
## .metric .estimator .estimate .config
## <chr> <chr> <dbl> <chr>
## 1 accuracy binary 0.891 Preprocessor1_Model1
## 2 roc_auc binary 0.941 Preprocessor1_Model1
Considerações finais
Existe, muito, mas muito mais que pode/poderia ser feito nesse pipeline. Ainda daria para verificar como as demais métricas de performance funcionam, extrair a matriz de confusão de cada uma delas, usar outras formas de tunagem/avaliação de performance.
Mas a ideia era dar uma pincelada no que é possível fazer com esse framework. Também não poderia deixar de citar o livro Tidy Modeling with R, que explica como usar o framework e de onde tudo desse post foi extraído. Ele conta com uma leitura muito fluida, simples e com ótimos exemplos reprodutíveis!
- Posted on:
- March 11, 2022
- Length:
- 11 minute read, 2135 words
- Categories:
- machine learning tidymodels
- See Also: