Segmentação de dados - Parte 1
By [map[name:Lucas Moraes.] map[url:https://lucasmoraes.org]] in k-prototypes segmentation unsupervised learning
September 28, 2021
Neste post, irei utilizar um algoritmo não supervisionado para classificar clientes em diferentes grupos.
A ideia básica é mostrar um passo-a-passo de como segmentar clientes a partir de um dataset misto e como os resultados podem ser visualizados. Além disso, também vou mostrar como implementar o modelo em diferentes contextos temporais, entendendo como os resultados podem mudar ao longo do tempo.
Este será o primeiro de uma série de posts, cada um tratando de um desses assuntos, uma vez que é muita coisa para um post só!
O modelo: K-prototypes
Existem diversas maneiras de fazer uma clusterização: podemos usar uma clusterização hierárquica, podemos usar o famoso k-means ou ainda diversos outros algoritmos.
Muitas vezes, porém, existem dois gargalos que podem limitar nossas análises no “mundo real”: performance e heterogeinidade de variáveis.
Quando falo de perfomance, falo de “memória” mesmo, do tempo que leva para a análise rodar (quando roda). Quando falo de heterogeinidade, falo de um dataset misto, que contém tanto variáveis contínuas/numéricas como variáveis discretas (numéricas ou não).
Nesse contexto, existe um algoritmo que funciona muito bem: o k-prototypes. Este, trata-se de uma espécie de junção dos famosos k-means e k-modes. Basicamente o que acontece é que nele, das variáveis contínuas são extraídas as médias (como no k-means) e das discretas são extraídas as modas (como no k-modes). Além disso, este é um algoritmo de alta performance, resolvendo os dois problemas citados anteriormente.
Em R, este pode ser implementado utilizando o pacote
{clustMixType}, que, por sinal, possui um excelente
paper de referência, explicando o funcionamento/funcionalidades do mesmo.
Tema da análise e limpeza do dataset
Nesta série de posts, vou trabalhar com dados de vendedores de e-commerce, utilizando dados da O-list, disponíveis no Kaggle!
Minha ideia é simples: quero segmentar esse dataset em grupos, que se assemelham/diferenciam em relação ao comportamento de suas variáveis. Esta é uma análise bem comum em empreendimentos que lidam com clientes, pois é natural que você queira entender como que seus clientes se segmentam.
Ainda assim, é importante destacar que esta ferramenta poderia ser utilizada em uma série de contextos: análisando fenômenos climáticos, espécies ou ainda dados financeiros.
Selecionando as variáveis
Existe uma quantidade gigantesca de informações que podem ser utilizadas na análise, uma vez que o dataset disponível é muito extenso. Vou focar em alguns dados em particular, mas é possível acessar uma explicação mais detalhada do dataset na página do Kaggle.
No dataset, existem informações tanto dos vendedores, quanto dos compradores de produtos, aqui vou focar em segmentar os vendedores e entender quais são as características que os une ou separa.
Destes, selecionei as variáveis abaixo:
seller_id: identificador dos vendedores. Não será utilizada na clusterização em si, mas em visualizações posteriores.payment_type: tipo de pagamento mais frequente feito nas vendas.product_category_name: categoria do produto mais vendido.top_review_score: nota mais frequente dada às revisões do vendedor (estrelas).total_orders: total de vendas.mean_price: preço médio dos produtos vendidos.mean_freight_value: preço médio do frete das vendas.mean_payment_value: preço médio total (produto + frete).birthdate: data de nascimento do vendedor (valor simulado).lifetime: tempo de vida do e-commerce do vendedor (valor simulado).seller_state: estado de origem do vendedor.
Essas informações foram todas compiladas na tabela abaixo:
seller_id <chr> | payment_type <chr> | |
|---|---|---|
| 0015a82c2db000af6aaaf3ae2ecb0532 | credit_card | |
| 001cca7ae9ae17fb1caed9dfb1094831 | credit_card | |
| 002100f778ceb8431b7a1020ff7ab48f | credit_card | |
| 003554e2dce176b5555353e4f3555ac8 | credit_card | |
| 004c9cd9d87a3c30c522c48c4fc07416 | credit_card | |
| 00720abe85ba0859807595bbf045a33b | credit_card | |
| 00ab3eff1b5192e5f1a63bcecfee11c8 | credit_card | |
| 00d8b143d12632bad99c0ad66ad52825 | credit_card | |
| 00ee68308b45bc5e2660cd833c3f81cc | credit_card | |
| 00fc707aaaad2d31347cf883cd2dfe10 | credit_card |
Para chegar nesse dataset, uma série de operações e sumarizações foram feitas nas tabelas do dataset original. Foge do escopo descrever esse processo, que é um pouco extenso. Entretanto, se você estiver interessado em entender como isso foi feito, eu te encorajo a conferir o .Rmd onde isso é feito,
no repositório que deu origem a esse post, ele está minimamente legível e anotado :)
Adicionalmente, tanto a data de nascimento como o lifetime dos clientes não está presente no dataset original, mas eu achei uma informação que seria interessante e por isso simulei estes valores. Eles não são, portanto, reais!
Definindo o número de clusters usando o Elbow Method
No algoritmo K-prototypes, o número de clusters no qual as observações serão agrupadas, é definido a priori, ou seja, devemos definir quantos serão antes de rodar a análise.
Este fato sempre levanta a questão: quantos clusters escolher?
Não existe resposta certa para essa pergunta, pois isso depende dos dados, da granularidade que queremos obter, entre outros fatores. Existem, entretanto, uma série de métodos que podem nortear esse processo, alguns explicados na própria documentação do
{clustMixType}, através da função validation_kproto.
Foge do escopo discutir os diferentes métodos, mas aqui opto por utilizar o elbow method (ou método do cotovelo). Neste, é executada uma série de clusterizações e, a partir de cada uma, calculada a variação intra cluster (na forma da soma dos erros quadrados intra cluster ou wss). A ideia é que aquela com menor valor de wss, tende a ser mais indicada como clusterização, pois esta indica uma maior estruturação dos mesmos. Ainda, queremos escolher o menor número viável de clusters, para não termos um modelo enviesado demais.
Felizmente, isso pode ser visualizado, o que facilita a intepretação dessa questão.
O gráfico abaixo, indica os valores de wss (eixo y), para cada clusterização feita com um determinado n de clusters definidos a priori (eixo x):
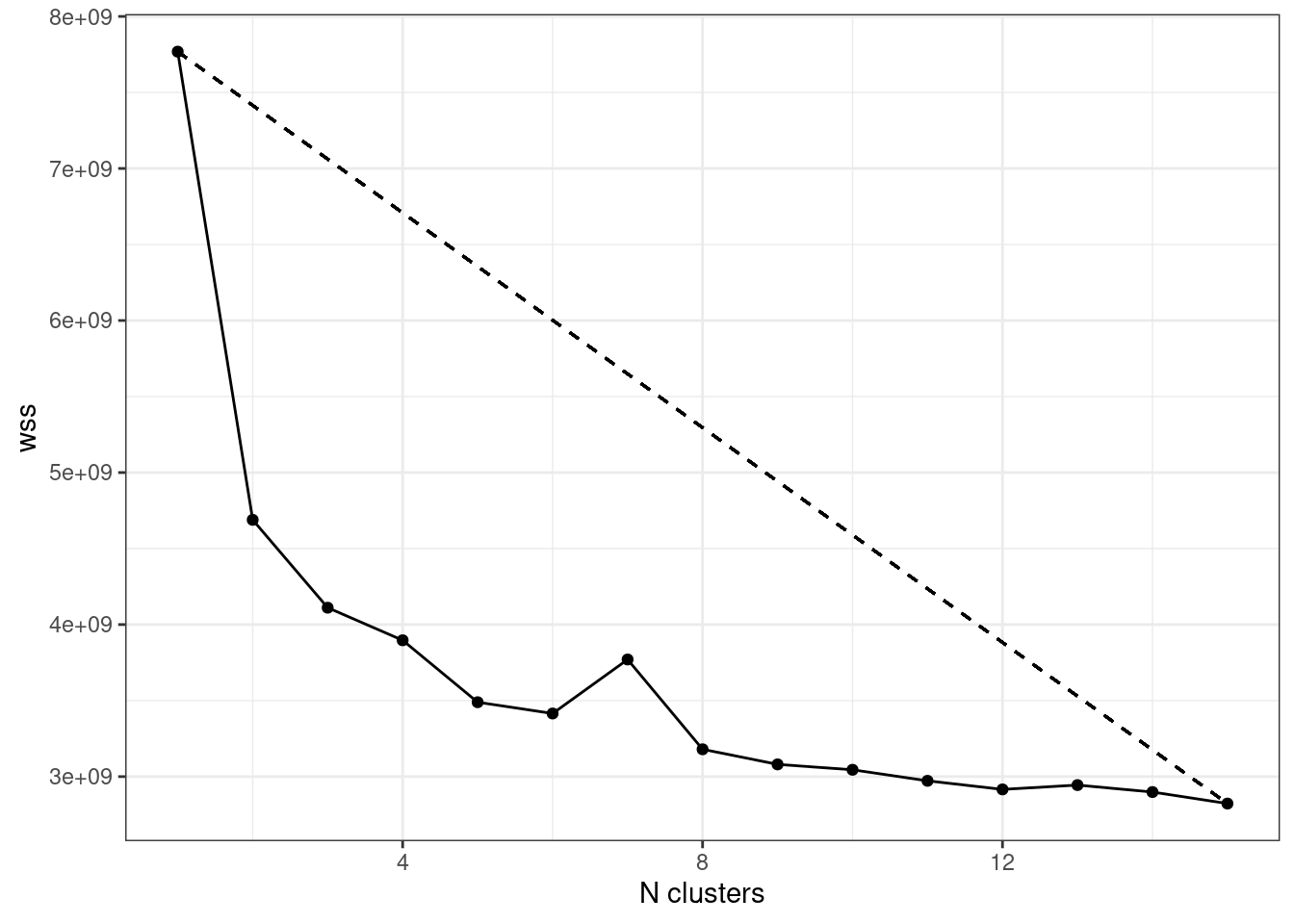
Queremos uma combinação entre um baixo wss e número de clusters. Isso pode ser quantificado a partir da distância de cada ponto em relação à reta que une os pontos com maior e menor valor de wss. Esse valor vai nos dar o melhor tradeoff de wss/n de clusters!
No caso acima, seria o modelo com 3 clusters, mas não é preciso fazer isso apenas no “olhômetro”. Esse gráfico foi extraído de uma tabela, que contém esses valores (ordenado em ordem crescente de distâncias até a reta):
x <int> | y <dbl> | distances <dbl> | ||
|---|---|---|---|---|
| 3 | 4111011166 | 6.7632292 | ||
| 5 | 3489318193 | 6.4228466 | ||
| 4 | 3896717998 | 6.3352876 | ||
| 2 | 4688903732 | 6.2205375 | ||
| 6 | 3415164374 | 5.6208012 | ||
| 8 | 3179754644 | 4.2492306 | ||
| 7 | 3770327866 | 3.6726877 | ||
| 9 | 3080408966 | 3.5144351 | ||
| 10 | 3044904302 | 2.6092153 | ||
| 11 | 2972314327 | 1.8029952 |
Vale enfatizar duas coisas: nada nos impede de usar mais ou menos clusters, sendo o elbow method uma abordagem holística. A outra, é que existem diversas maneiras de calcular o número ótimo de clusters para as análises, fato já mencionado.
Já sabemos então que uma análise com 4 clusters é um bom ponto de partida para segmentar o nosso dataset. Então agora é rodar a clusterização usando o número escolhido. Para fazer isso vou utilizar o dataset que já está pronto e executar a função kproto, definindo o número de clusters como 4. Vou armazenar resultado em um objeto denominado client_segmentation:
## # NAs in variables:
## payment_type product_category_name top_review_score
## 0 0 0
## total_orders mean_price mean_freight_value
## 0 0 0
## mean_payment_value lifetime seller_state
## 0 0 0
## idade
## 0
## 0 observation(s) with NAs.
##
## Estimated lambda: 411758.4
payment_type <fct> | product_category_name <fct> | ||
|---|---|---|---|
| 1 | credit_card | eletroportateis | |
| 2 | credit_card | ferramentas_jardim | |
| 3 | credit_card | moveis_decoracao | |
| 4 | credit_card | indefinido | |
| 5 | credit_card | cama_mesa_banho | |
| 6 | credit_card | utilidades_domesticas | |
| 7 | credit_card | beleza_saude | |
| 8 | credit_card | fashion_bolsas_e_acessorios | |
| 9 | credit_card | cama_mesa_banho | |
| 10 | credit_card | informatica_acessorios |
Um dos outputs dessa função é a tabela acima, que destaca os valores médios ou valores mais frequentes (dependendo do tipo de dado) de cada cluster formado.
Para algumas variáveis parece repetitivo, mas isso pode ser investigado mais a fundo com mais clusterizações e uma boa análise exploratória. Além disso, existem outros atributos vinculados a esse objeto (de classe k-proto) que também podem ser analisadas.
Este será o tema do próximo post: explorar os resultados da clusterização(ões)!
- Posted on:
- September 28, 2021
- Length:
- 6 minute read, 1159 words
- Categories:
- k-prototypes segmentation unsupervised learning
- See Also: